|
I am currently a research scientist at Sony AI, where I worked with Private-Preserving Machine Learning (PPML) teams for developing privacy-preserving vision solutions. My research interest lies in Federated Learning with focus on its practicality and utility in challenging real-world applications.
Email / CV / Google Scholar / Linkedin / Github |

|
|
My past research projects conver a wide range of security problems in edge DNN systems, including parameter security, data security and architecture IP security. Representative papers are highlighted. |
|
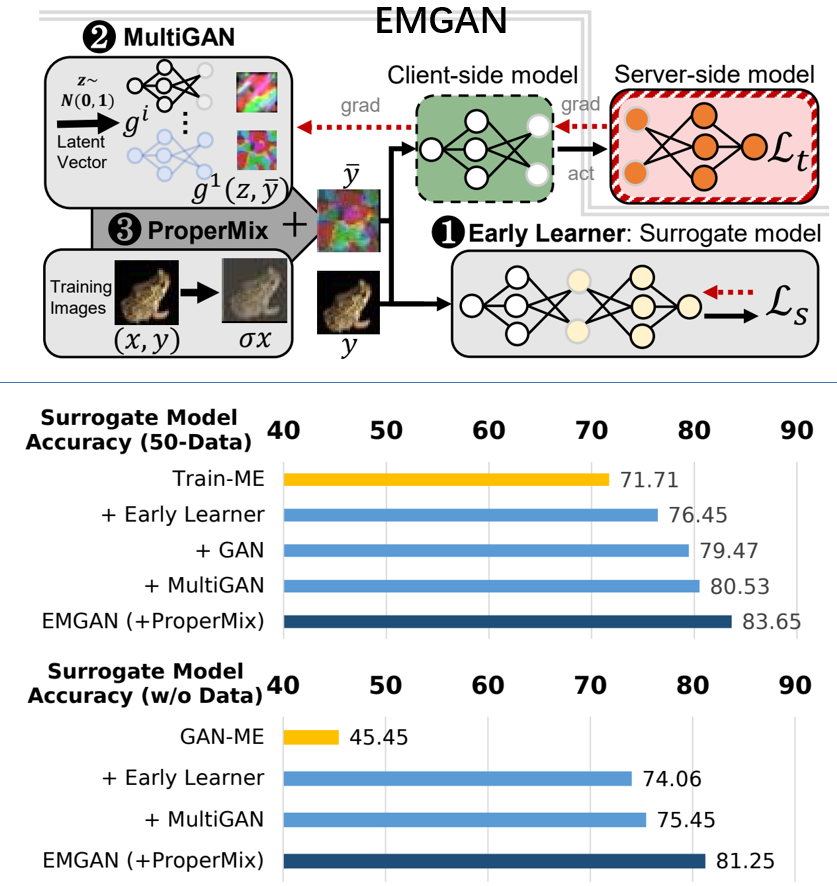
Jingtao Li, Xing Chen, Li Yang, Adnan Siraj Rakin, Deliang Fan, Chaitali Chakrabarti AAAI, 2024 Paper / Code We propose a strong MEA attack against Split Federated Learning, Early-Mix-GAN (EMGAN) attack. EMGAN attack effectively exploits gradient queries regardless of data assumptions and adopts three novel designs to address the problem of inconsistent gradients. Specifically, it employs (i) Early-learner approach for better adaptability, (ii) Multi-GAN approach to introduce randomness in generator training to mitigate mode collapse, and (iii) ProperMix to effectively augment the limited amount of synthetic data for a better approximation of the target domain data distribution. |
|
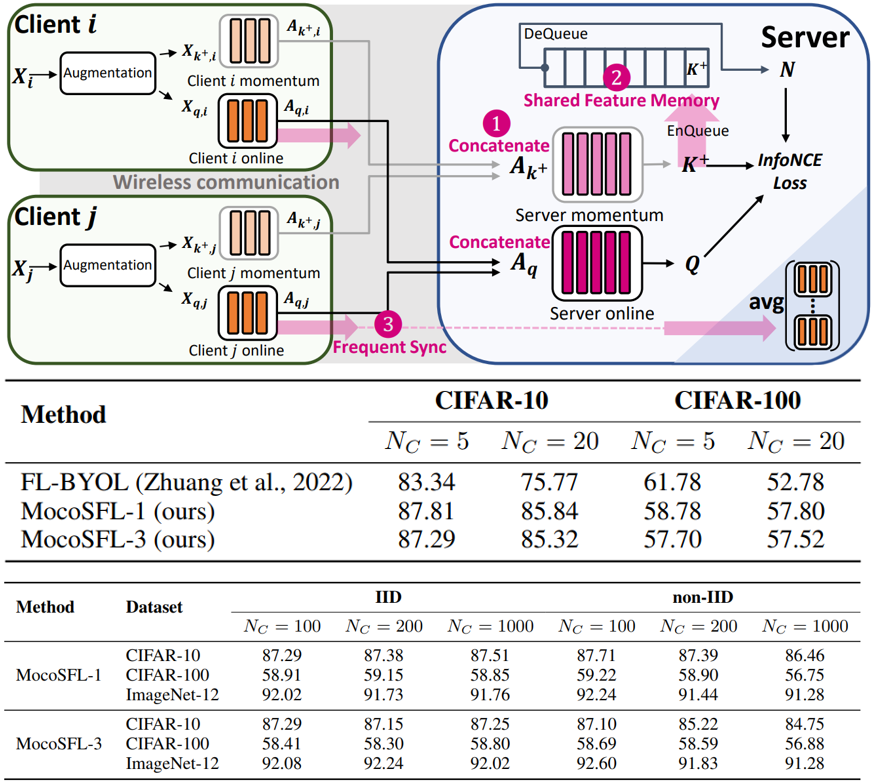
Jingtao Li, Lingjuan Lyu, Daisuke Iso, Chaitali Chakrabarti, Michael Spranger, ICLR (oral, notable-5%), 2023 Paper / Code (soon) We propose MocoSFL, a collaborative SSL framework based on SFL and MoCo to resolve the harsh hardware and data requirement of Federated Self-supervised Learning schemes. Our empirical results show the proposed MocoSFL scheme achieves much better Non-IID performance than state-of-the-art FedSSL, and it can scale to 1,000-client with ultra-low hardware requirement. |
|
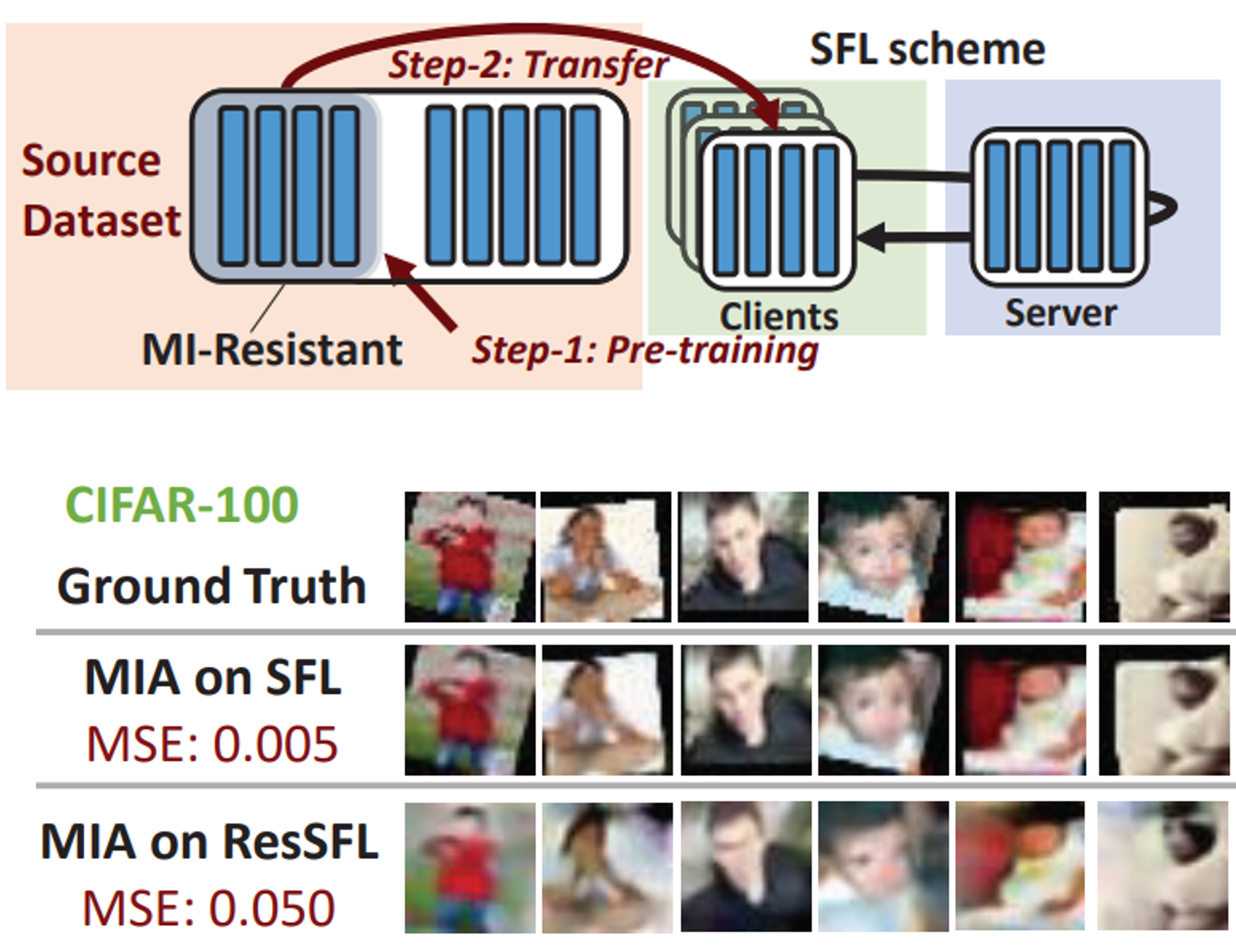
Jingtao Li, Adnan Siraj Rakin, Xing Chen, Zhezhi He, Deliang Fan, Chaitali Chakrabarti CVPR, 2022 Paper / Code We develop a two-step “adversarial training + transfer learning” framework called ResSFL to resolve the privacy issue in Split Federated Learning. ResSFL mitigates the data privacy threat of SFL and makes model inversion attacks 10 times harder to succeed, with only a less than 1% drop in model accuracy. |
|
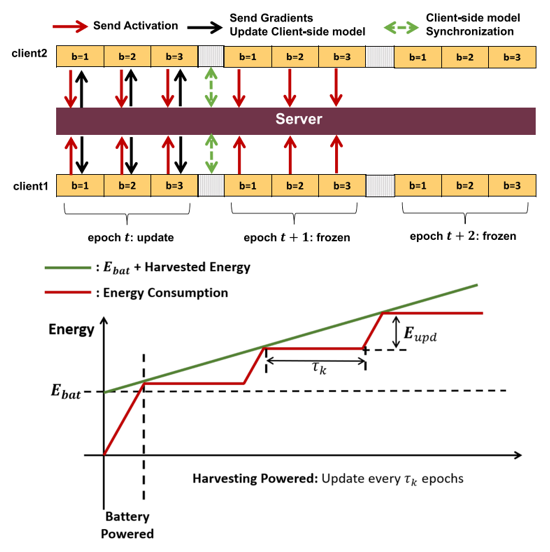
Xing Chen, Jingtao Li, Chaitali Chakrabarti Journal of Signal Processing Systems (JSP) Paper /Code (soon) We design an energy+loss-aware communication reduction scheme for SFL that successfully saves total energy consumption by 43.7% to 80.5% with only a 0.5% sacrifice in model accuracy for VGG-11 and ResNet-20 models on CIFAR-10 and CIFAR-100 datasets. |
|
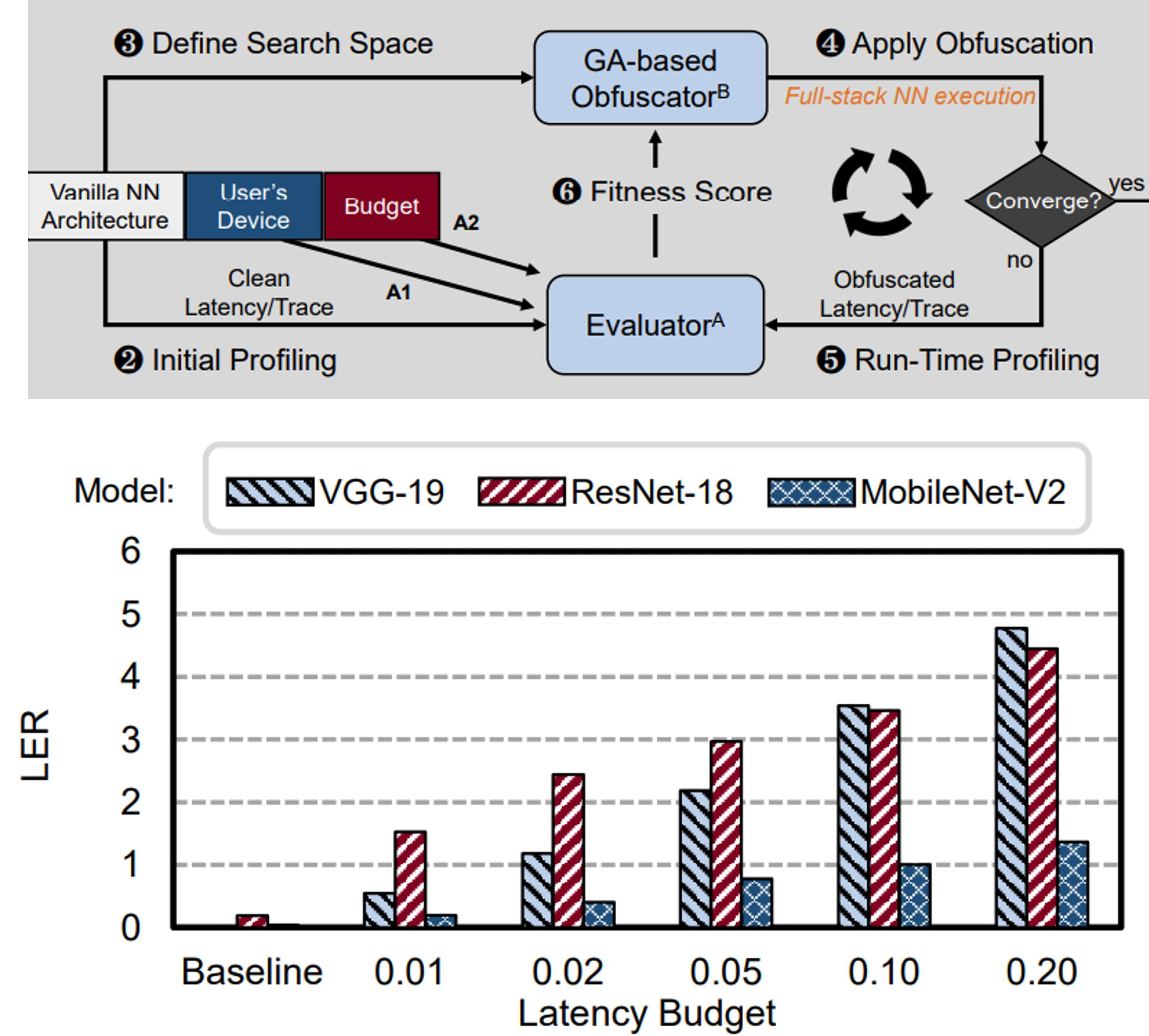
Jingtao Li, Zhezhi He, Adnan Siraj Rakin, Deliang Fan, Chaitali Chakrabarti HOST, 2021 Paper / Code We propose NeurObfuscator, a full-stack DNN model processing obfuscation framework embedded in the compilation of a DNN model to prevent neural architecture stealing. The obfuscated model generates drastically different hardware traces and successfully fools a potential architecture thief by keeping fast execution and equivalent model functionality. Results on sequence obfuscation show that the proposed tool obfuscates a ResNet-18 ImageNet model to a totally different architecture (with 44 layer difference) without affecting its functionality with only 2% overall latency overhead. |
|
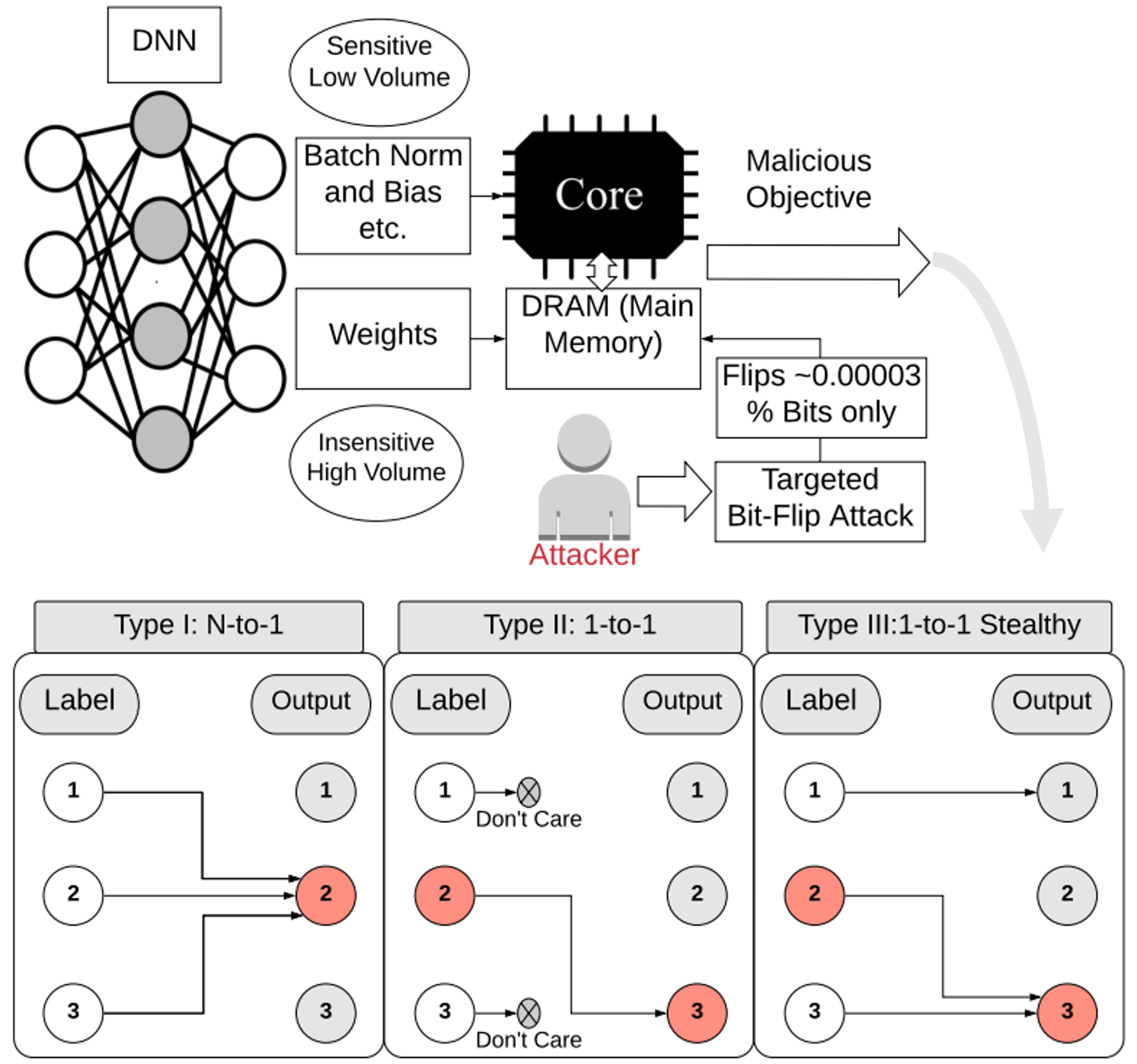
Adnan Siraj Rakin, Zhezhi He, Jingtao Li, Fan Yao, Chaitali Chakrabarti, Deliang Fan TPAMI Paper / Code We propose the first work of targeted BFA based (T-BFA) adversarial weight attack on DNNs, which can intentionally mislead selected inputs to a target output class. By merely flipping 27 out of 88 million weight bits of ResNet-18, our T-BFA can misclassify all the images from Hen class into Goose class (i.e., 100% attack success rate) in ImageNet dataset, while maintaining 59.35% validation accuracy. |
|
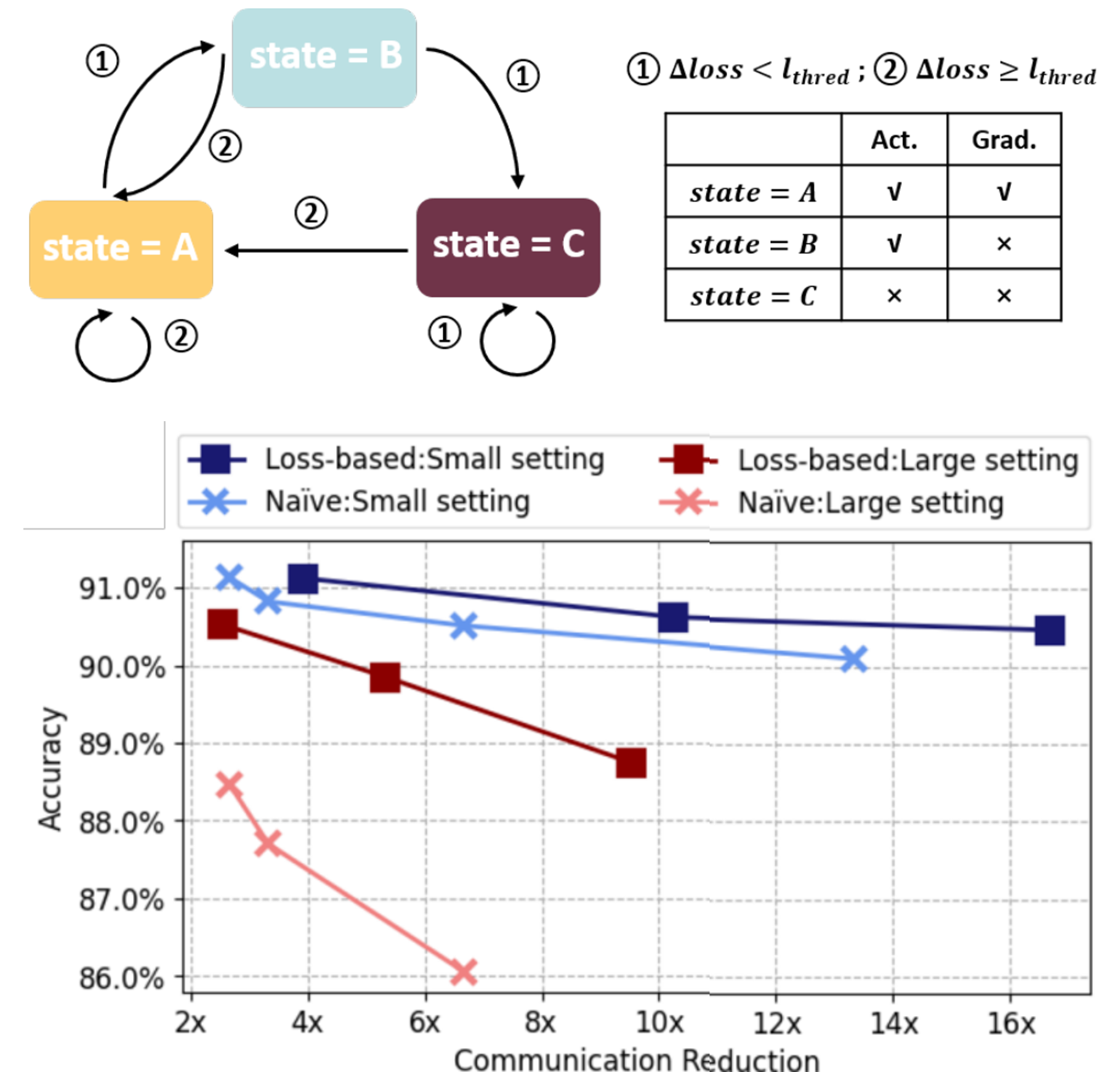
Xing Chen, Jingtao Li, Chaitali Chakrabarti IEEE-SIPS Paper / Code We propose a loss-based asynchronous training scheme to effectively reduce the communication and computation overhead of Split Learning. Simulation results on VGG-11, VGG-13 and ResNet-18 models on CIFAR-10 show that the communication cost is reduced by 1.64x-106.7x and the computations in the client are reduced by 2.86x-32.1x when the accuracy degradation is less than 0.5%. |
|
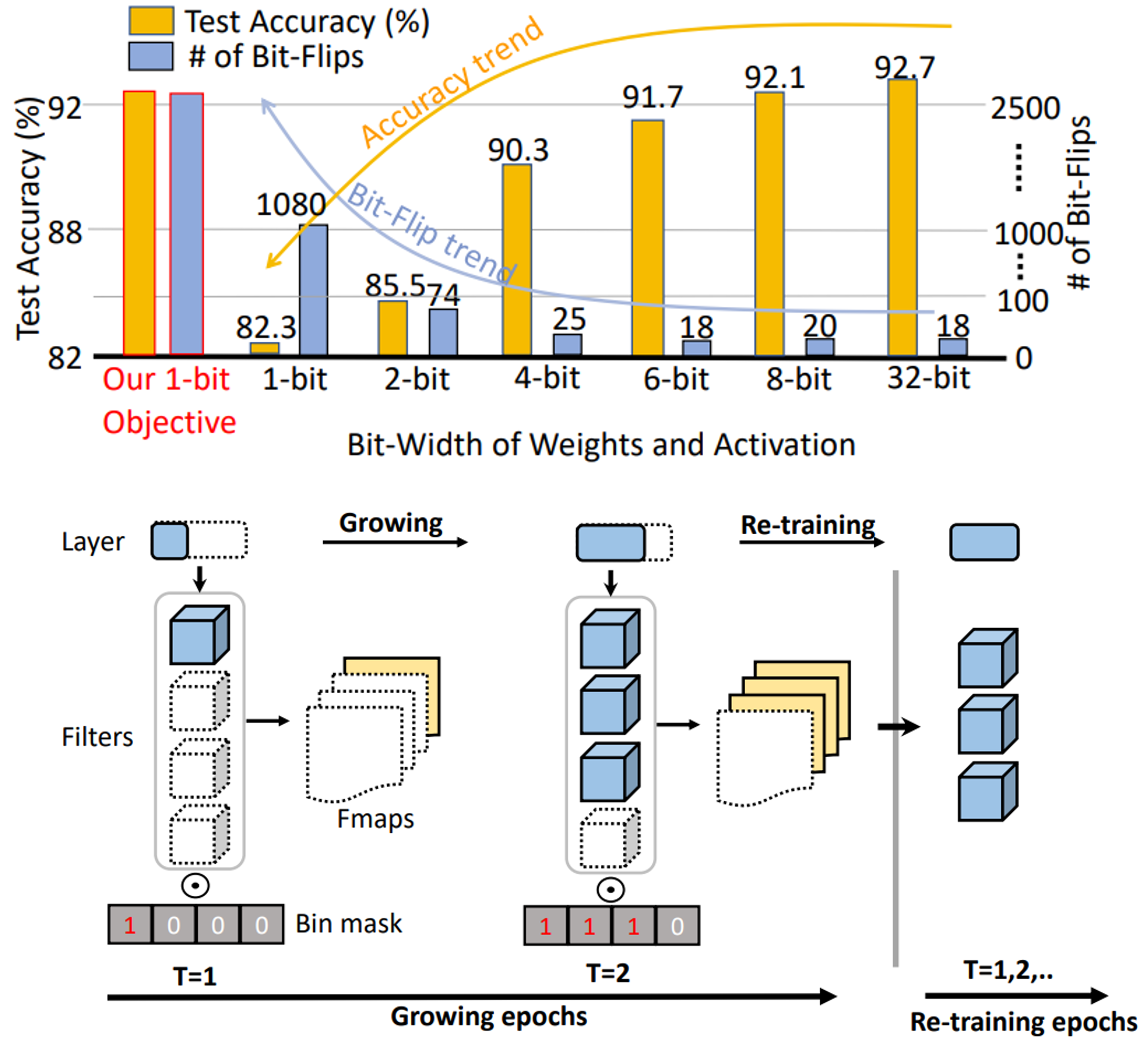
Adnan Siraj Rakin, Yang Li, Jingtao Li, Fan Yao, Chaitali Chakrabarti, Yu Cao, Jae-son Seo, Deliang Fan Arxiv (Major Revision, TPAMI) Paper / Code We propose RA-BNN that adopts a complete binary neural network to significantly improve DNN model robustness. Our evaluation of the CIFAR-10 dataset shows that the proposed RA-BNN can improve the clean model accuracy by ~2-8 %, compared with a baseline BNN, while simultaneously improving the resistance to BFA by more than 125 x. |
|
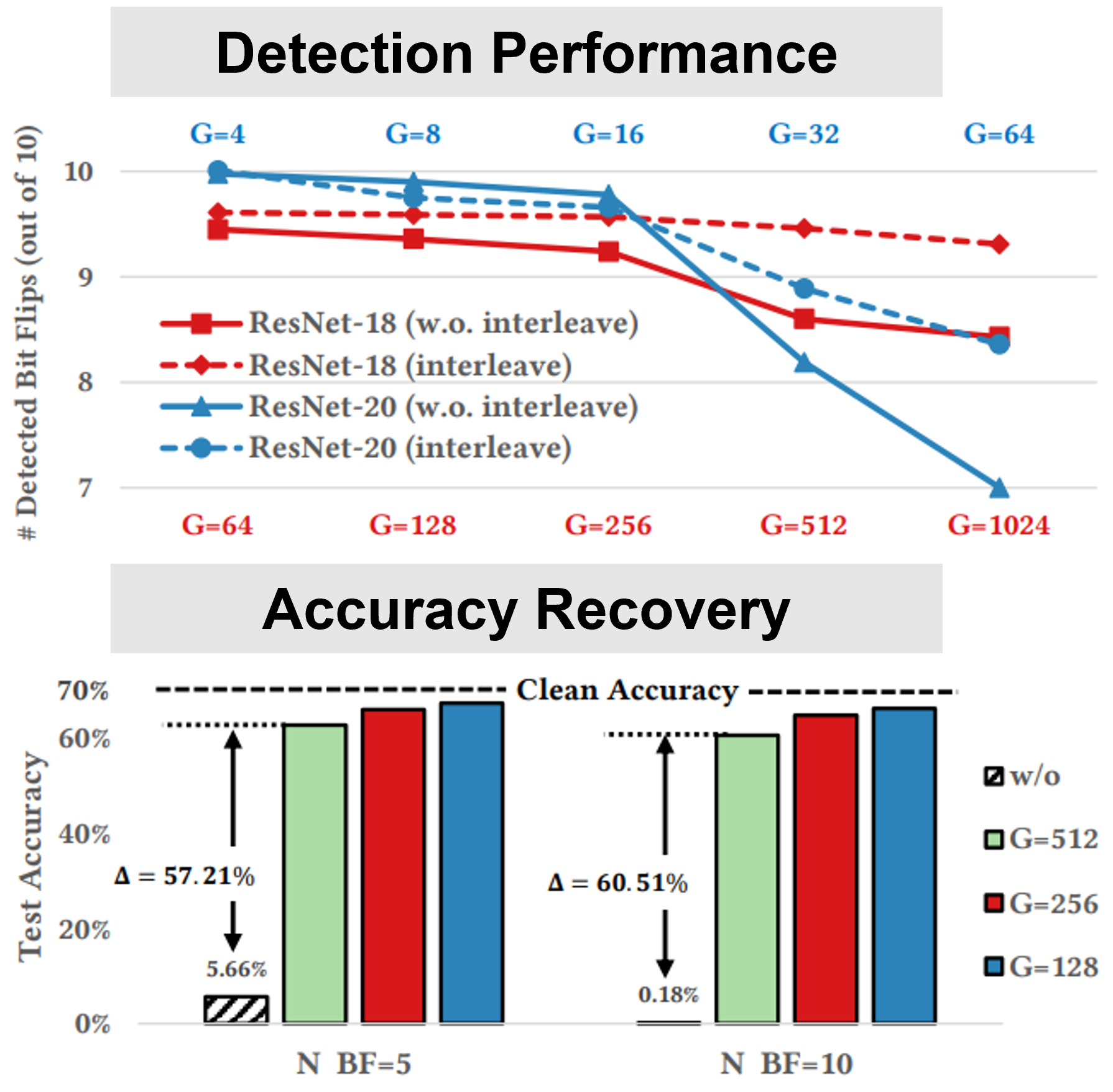
Jingtao Li, Adnan Siraj Rakin, Zhezhi He, Deliang Fan, Chaitali Chakrabarti DATE, 2021 Paper / Code We present RADAR, the first work of detecting bit-flip attack on machine learning systems, with a light-weight fast checking & recovery mechanism. For this model, the proposed accuracy recovery scheme can restore the accuracy from below 1% caused by 10 bit flips to above 69%. System-level simulation on gem5 shows that RADAR only adds < 1% to the inference time, making this scheme highly suitable for run-time attack detection and mitigation. |
|
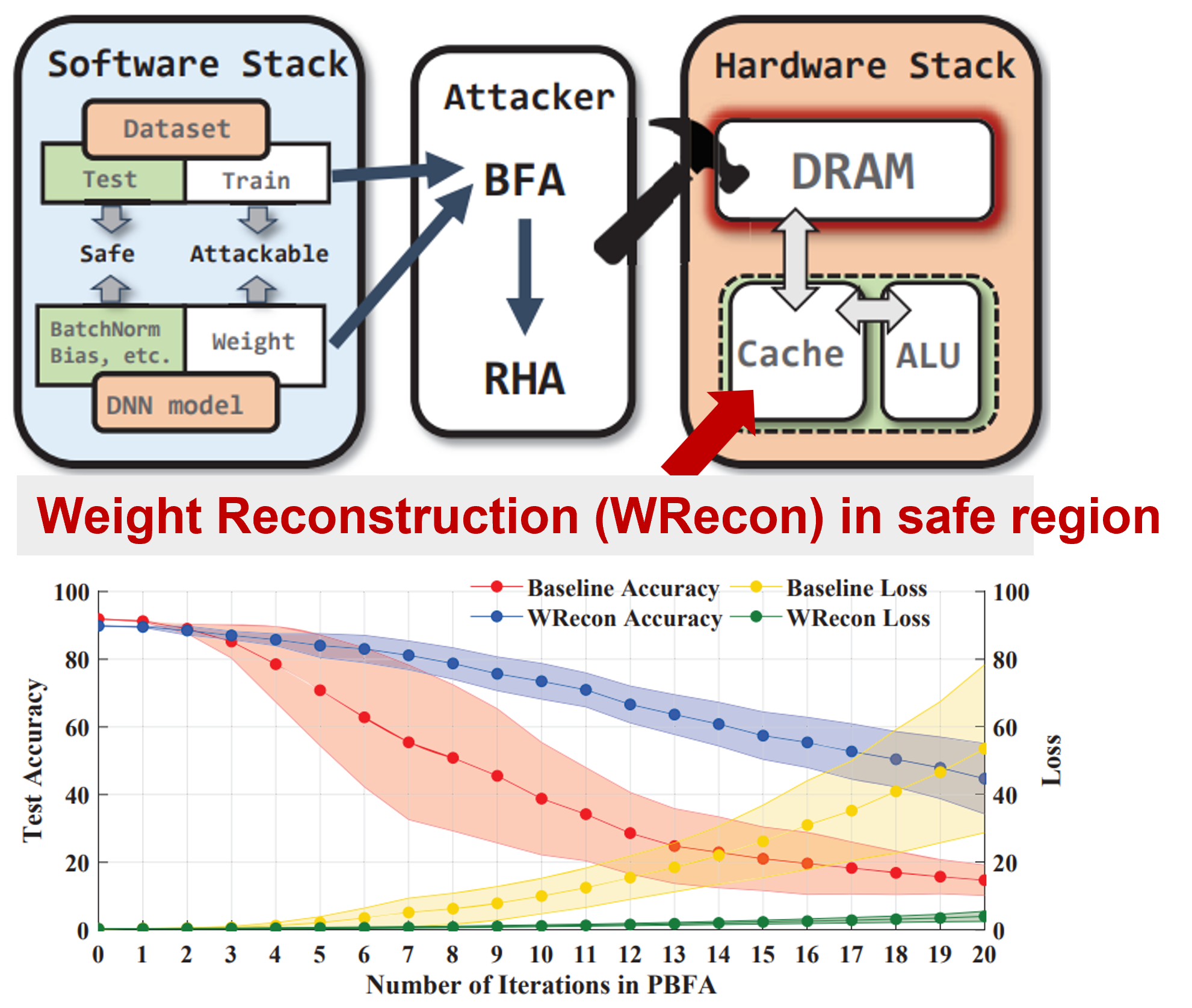
Jingtao Li, Adnan Siraj Rakin, Yan Xiong, Liangliang Chang, Zhezhi He, Deliang Fan, Chaitali Chakrabarti DAC, 2020 Paper / Code We propose a novel weight reconstruction method that effectively mitigate bit-flips on quantized neural networks, either happen naturally or injected by malicious attackers. Even under the most aggressive attack (i.e., BFA), our method maintains a test accuracy of 60% on ImageNet after 5 iterations while the baseline accuracy drops to below 1%. |
|
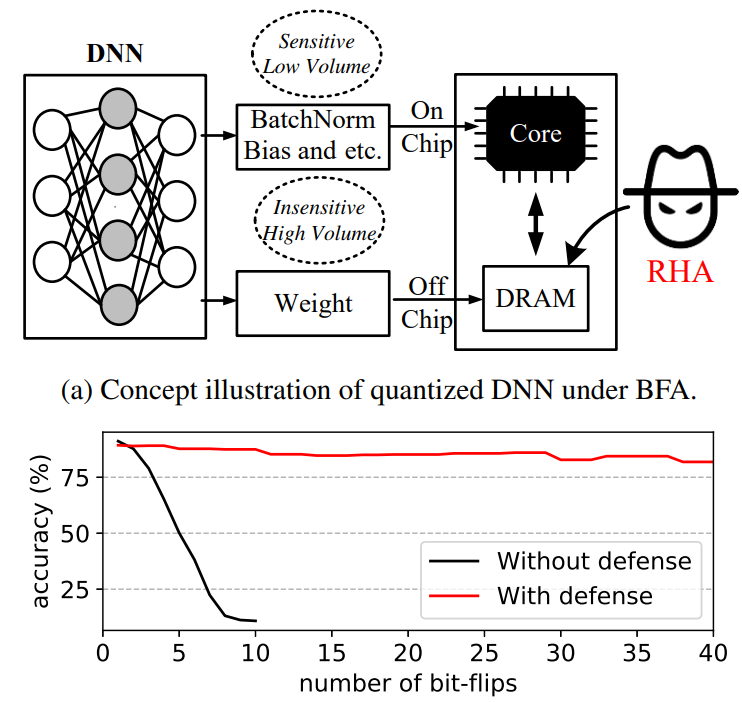
Zhezhi He, Adnan Siraj Rakin, Jingtao Li, Chaitali Chakrabarti, Deliang Fan CVPR, 2020 Paper / Code We propose piece-wise clustering as simple and effective countermeasures to BFA. The experiments show that, for BFA to achieve the identical prediction accuracy degradation (eg, below 11% on CIFAR-10), it requires 19.3 x and 480.1 x more effective malicious bit-flips on ResNet-20 and VGG-11 respectively, compared to defend-free counterparts. |
|
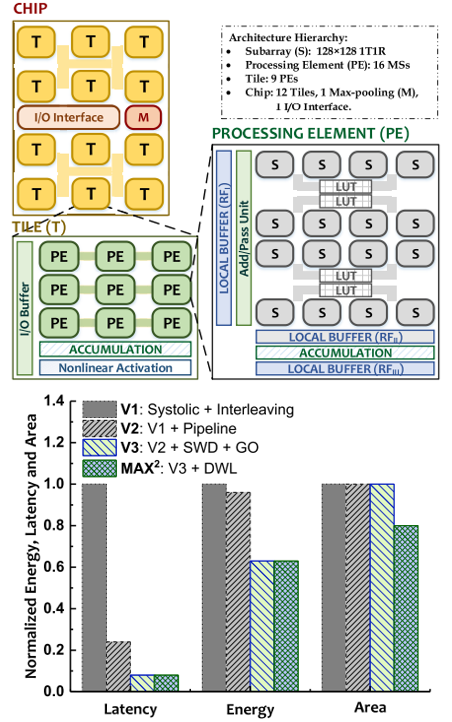
Manqing Mao, Xiaochen Peng, Rui Liu, Jingtao Li, Shimeng Yu, Chaitali Chakrabarti JETCAS Paper We propose MAX2, a multi-tile ReRAM accelerator framework for supporting multiple CNN topologies, that maximizes on-chip data reuse and reduces on-chip bandwidth to minimize energy consumption due to data movement. The system-level evaluation in 32-nm node on several VGG-network benchmarks shows that the MAX2 can improve computation efficiency (TOPs/s/mm2) by 2.5x and energy efficiency (TOPs/s/W) by 5.2x compared with a state-of-the-art ReRAM-based accelerator. |
|
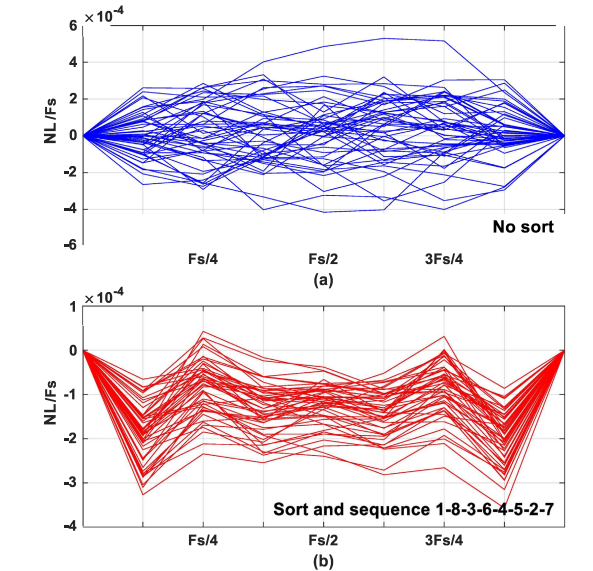
Hua Fan, Jingtao Li, Franco Maloberti TCAS-I Paper / Code We propose ordering technique to improve the static linearity performances of digital-to-analog converters with in-depth study in grouping/sequencing elements in segmented, binary and unary DAC architectures. Results show that the use of segmented architecture with 8~16 groups of elements sorted and optimally selected grants 2~3 bits more in the performance. |
|
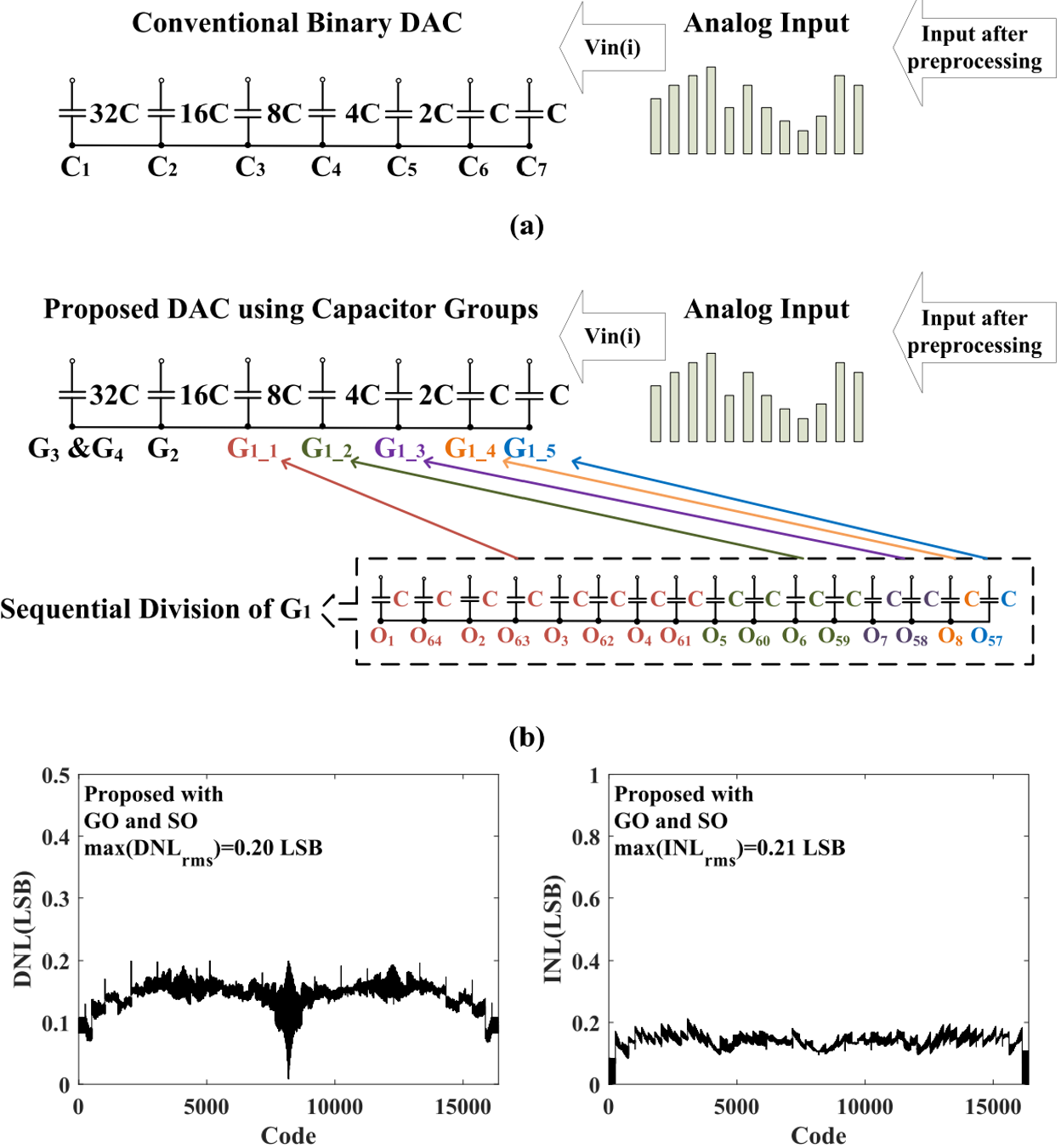
Hua Fan, Jingtao Li, Quanyuan Feng, Xiaopeng Diao, Lishuang Lin, Kelin Zhang, Haiding Sun, Hadi Heidari IEEE Access Paper / Code We present a statistics-optimized organization technique to achieve better element matching in successive approximation register (SAR) analog-to-digital converter (ADC). We demonstrate the proposed technique ability to achieve a significant improvement of around 23 dB on a spurious free dynamic range (SFDR) of the ADC than the conventional, testing with a capacitor mismatch of 0.2% in a 14-bit SAR ADC system. |
|
I have reviewed ICML (2024), ICLR (2024), CVPR (2024), AAAI (2024), ISCAS (2024), Neurips (2023), ICCV (2023), CVPR (2023), ECCV (2022), CVPR (2022), ISCAS (2022), and GLSVLSI (2020). I am also the Reviewer of journals IEEE TPDS, IEEE ESL, IEEE TGCN, IEEE TCSVT, IEEE JETCAS, IEEE TPAMI. |
|
Source code credit to Dr. Jon Barron |